

原标题:我们如何处理大型 Python 单体架构
作者 | David Seddon
译者 | 平川
策划 | Tina
本文最初发布于 EuroPyhon 官方博客。
大家好,我叫 David,是 Kraken Technologies 的一名 Python 开发人员。我从事 Kraken 开发,那是一个 Python 应用程序。据最新统计,它有 27,637 个模块。是的,你没看错:将近 28k 个独立的 Python 文件,这还不包括测试。我和世界各地的其他 400 名开发人员一起做这件事,不断地合并代码。任何人只要在 Github 上得到一个同事的批准,就可以做出变更,开始部署这个运行着 17 家不同的能源和公用事业公司、拥有数百万客户的软件。
现在,你可能觉得这会很混乱。说实话,我也会这么说。但事实证明,大量的开发人员可以在一个大型的 Python 单体上有效地开展工作,至少在我们工作的领域是如此。这是可能的,原因有很多,很多是文化上的,而不是技术上的。但在这篇博文中,我想介绍一下代码的组织如何帮助我们实现这一目标。
代码库分层
如果你在某个代码库上做过一段时间的开发,那么你肯定感受过那令人不快的复杂性。应用程序的逻辑链错综复杂,想要独立地考虑应用程序的各个部分变得越来越困难。我们的代码库开始时也是这样,所以我们决定采用所谓的“分层架构”,对代码库层与层之间哪些部分可见做了限制。
分层是一种众所周知的软件架构模式。在这种模式中,组件在概念上被组织成一个栈。栈中的组件不能依赖于上层的任何组件。
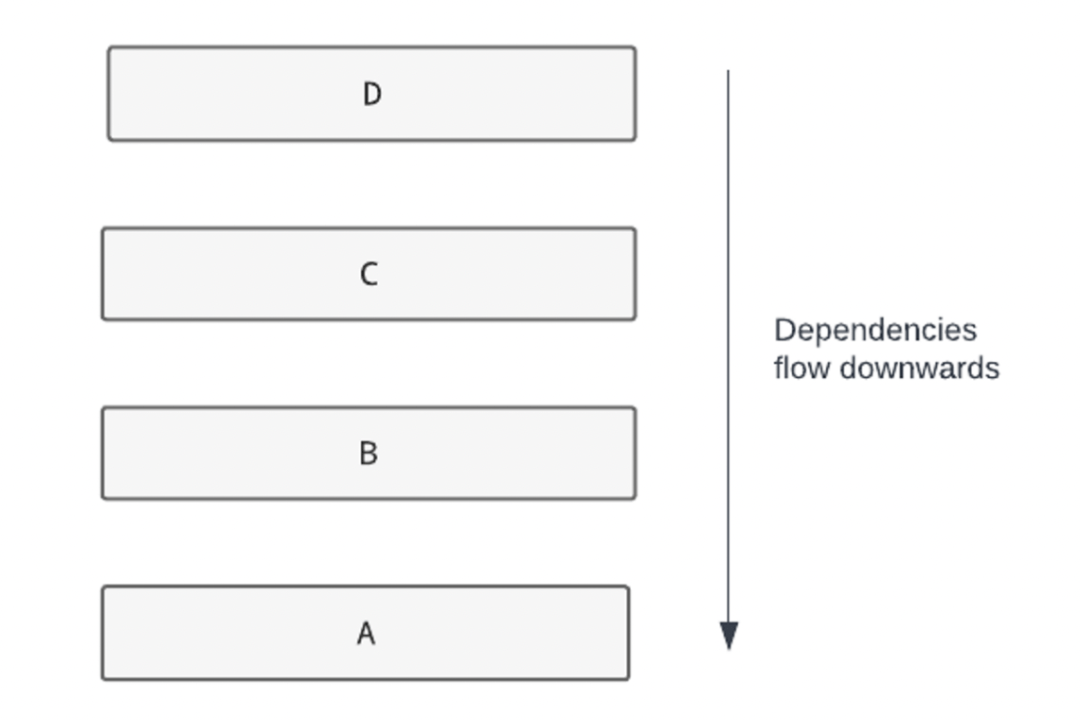
分层架构,向下依赖
如上图所示,C 可以依赖 B 和 A,但不能依赖 D。
分层架构的概念很广泛:它可以用于不同类型的组件。例如,你可以将几个可独立部署的服务分层;或者,你的组件可以只是一组源代码文件。
依赖的构成也很广泛。一般来说,如果一个组件对另一个组件有直接的了解(即使纯粹是在概念层面),那么它就依赖于另一个组件。间接交互(例如,通过配置)通常不视为依赖。
Python 中的分层
在 Python 代码库中,最好将层视为 Python 模块,将依赖视为 import 语句。
以下面的代码库为例:
myproject __init__.py payments/ __init__.py api.py vendor.py products.py shopping_cart.py顶层模块和子包是层的良好候选。假设我们按下面这样的顺序分层:
shopping_cart payments products那么,在这个架构中,shopping_cart 不能导入 payments 中的任何模块。不过,它可以导入 products 的模块。
层可以嵌套。因此,payments 可以像下面这样分层:
api vendor至于分成几层以及各层之间的顺序,并没有一种唯一正确的方法,这是一种设计行为。但是像这样的分层可以减少代码库的混乱,使其更容易理解和修改。
Kraken 是如何分层的
在我写这篇文章时,有 17 家不同的能源和公用事业公司批准了 Kraken 的使用。我们为这些企业客户中的每一个运行一个单独的实例。现在,Kraken 的主要特点之一是不同的实例“相同又不同”。换句话说,它们之间有很多共享的行为,但每个实例都有满足特定客户需求的定制代码。在地区层面上也是如此:在英国运营的所有客户之间存在一些共性(它们与同一能源行业相融合),但与 Octopus Energy Japan 不同。
随着 Kraken 发展成为一个多客户平台,我们改进了它的分层结构。总的来说,现在的情况是这样的:
kraken/ __init__.py clients/ __init__.py oede/ oegb/ oejp/ … territories/ __init__.py deu/ gbr/ jpn/ … core/客户位于顶层。每个客户对应该层中的一个子包(例如,oede 对应 Octopus Energy Germany)。客户的下面是地区,实现特定于国家的行为,同样,每个地区对应一个子包。最下层是核心层,其中包含所有客户都使用的代码。还有一个额外的规则,即客户子包必须是独立的(即不能从其他客户包导入),对于地区同样如此。
像这样把 Kraken 分层可以有效限制变更的“爆炸半径”。由于客户层位于顶部,所以没有任何东西直接依赖于它。因此,要修改与特定客户相关的内容会比较容易,而且不会意外影响其他客户的行为。同样,只涉及一个地区的更改也不会影响到另一个地区的任何东西。这使得我们能够快速独立地跨团队开展工作,特别是当我们正在进行的更改仅影响少量 Kraken 实例时。
利用 Import Linter 强制分层
当我们引入分层时,我们很快就发现,仅仅讨论分层是不够的。开发人员经常会不小心违反分层结构。我们需要以某种方式强制执行,为此,我们使用了 Import Linter。
Import Linter 是一个开源工具,可以检查你是否遵守了分层架构。首先,在 INI 文件中定义一个契约,用于描述分层,像下面这样:
[importlinter:contract:top-level]name = Top level layerstype = layerslayers =kraken.clientskraken.territoriesKraken.core
我们也可以另外添加两个契约(‘independence’契约),强制保持不同客户和地区的独立性:
[importlinter:contract:client-independence]name = Client independencetype = independencelayers =kraken.clients.oedekraken.clients.oegbkraken.clients.oejp…[importlinter:contract:territory-independence]name = Territory independencetype = independencelayers =kraken.territories.deukraken.territories.gbrkraken.territories.jpn…
然后,你可以在命令行上运行 lint-imports,它会告诉你是否有任何导入违反了契约。每次有 pull 请求时都会自动执行这个命令进行检查,所以如果有人引入了非法导入,就无法通过检查,也就无法完成合并。
契约不只这些。团队可以在应用程序中添加更深的分层:例如,kraken.territories.jpn 本身就是分层的。目前,我们有 40 多个契约。
减少技术债务
在引入分层架构时,我们没法从第一天开始就严格遵守。所以我们使用了 Import Linter 的一个特性,在检查契约之前忽略某些导入。
[importlinter:contract:my-layers-contract]name = My contracttype = layerslayers =kraken.clientskraken.territorieskraken.coreignore_imports =kraken.core.customers ->kraken.territories.gbr.customers.viewskraken.territories.jpn.payments -> kraken.utils.urls(and so on…)然后,我们使用被忽略导入的数量作为跟踪技术债务的指标。这使我们能够了解改进情况,以及改进速度。

自 2022 年 5 月 1 日起被忽略导入的数量
上图是在过去一年左右的时间里,被忽略导入的数量变化情况。我定期向人们进行分享和展示,鼓励他们朝着完全遵守依赖原则的方向努力。我们在其他几个技术债务指标中也使用了这种燃尽方法。
缺点,缺点总是不可避免
局部复杂性
在采用分层架构之后的某个时刻,你可能会遇到需要打破分层的情况。实际情况会非常复杂,到处都是相互依赖,比如,你会发现自己想要调用一个更高层的函数。
幸运的是,办法总比问题多。我们可以利用控制反转,那在 Python 中很容易实现,所需的只是理念的转变。但它确实会增加“局部”的复杂性(如代码库的一小部分)。然而,为了使系统总体上更简单,付出这样的代价是值得的。
较高的层上代码过多
层越高,越容易更改。我们是有意为之的,让针对特定客户或地区的代码更容易更改。其他所有的层都要依赖于核心代码,对其进行修改的成本和风险也都更高。
因此,我们面临的设计压力部分是由我们选择的分层结构带来的,我们需要编写更多特定于客户和地区的代码,而不是在核心代码中引入更深的层次和更多可供全局使用的代码。因此,较高的层所拥有的代码超出了我们的预期。我们仍在研究如何解决这个问题。
我们还没有完成
还记得那些被忽略的导入吗?好吧,几年过去了,我们还是有一些!据最新统计,有 15 个。最后几项导入是最棘手、让人最纠结的。
回顾性地对代码库进行分层可能需要付出很大的努力。但这件事你做得越早,需要解决的问题就越少。
小 结
Kraken 的分层架构使我们这个非常庞大的代码库得以保持健康,并且相对比较容易使用,尤其是在这么个规模下。如果不对这成千上万的模块之间的关系施加约束,我们的代码库可能就会变成一大盘意大利面。但是,我们选择的这个大规模结构——并且随着业务的发展而发展——帮助我们在单个 Python 代码库上做了大量的工作。这似乎是不可能的,但我们确实做到了!
如果你正在处理大型 Python 代码库(甚至是相对比较小的代码库),不妨试一下分层。这事越早做越简单。
原文链接:
https://blog.europython.eu/kraken-technologies-how-we-organize-our-very-large-pythonmonolith/
谷歌重磅发布多平台应用开发神器:背靠 AI 编程神器 Codey,支持 React、Vue 等框架,还能补全、解释代码
IPv4 开始收费!新的 IT 灾难?
爱奇艺VR公司业务停滞,员工或被欠薪;阿里云开源通义千问 70 亿参数模型,免费可商用;华为正式发布鸿蒙 4,接入大模型|Q资讯
年薪超 600 万,比技术总监还高:电影行业 AI 产品经理的崛起返回搜狐,查看更多
责任编辑: