

变量是编程中的一个核心概念,用于存储可以在程序执行过程中改变的值。它们用于表示各种类型的数据,如整数、浮点数、字符或对象引用等。在Java中,变量是存储数据的基本单元,并且每个变量都有特定的数据类型,这决定了变量可以存储什么类型的值以及可以进行的操作。
在Java中定义变量时,需要指定变量的类型,这告诉编译器变量可以存储的数据种类。例如,int类型变量用于存储整数,而double类型变量用于存储双精度浮点数。变量在声明时还可以被赋予一个初始值,或者如果未指定初始值,它们将自动被赋予一个默认值,通常是该类型的零值(如0对于数值类型,null对于引用类型)。
一旦变量被声明和初始化,就可以在程序的后续部分中通过赋值操作改变其值。这种重新赋值的能力使得变量能够在程序执行的不同阶段存储和反映不同的数据状态。此外,一个变量的值也可以被复制给另一个变量,这允许在不同变量之间共享数据。
下面是一个示例代码,它演示了如何在Java中声明、初始化和使用变量:
public class Main {
public static void main(String[] args) {
// 声明并初始化一个整型变量x,赋值为100
int x = 100;
// 打印变量x的值
System.out.println("x的初始值是: " + x);
// 重新为变量x赋值,赋值为200
x = 200;
// 再次打印变量x的值
System.out.println("x的新值是: " + x);
// 声明一个新的整型变量n,并将x的值赋给它
int n = x;
// 打印变量n的值
System.out.println("n的值是: " + n);
// 对变量x进行加法操作,并将结果存回变量x
x = x + 100;
// 打印变量x的新值
System.out.println("x的新值是: " + x);
// 打印变量n的值,注意n的值并没有因为x的改变而改变
System.out.println("n的值仍然是: " + n);
}
}在这个示例中,我们展示了如何声明和初始化变量,如何给变量重新赋值,以及如何将一个变量的值赋给另一个变量。我们还演示了变量值的变化不会影响到其他变量,除非显式地进行了赋值操作。这是理解变量作用域和生命周期的关键概念。
我们逐行分析代码的执行流程来深入了解变量是如何工作的:
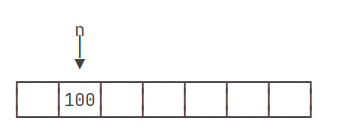
首先,执行int n = 100;这行代码时,Java虚拟机(JVM)会在内存中为变量n分配一个存储单元,并将整数100存储在这个单元中。此时,n的值是100。
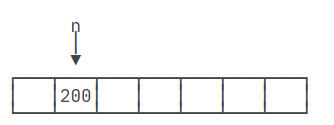
接下来,执行n = 200;时,JVM会将变量n的存储单元中的值从100更新为200。这意味着原来的值100被新的值200所覆盖。
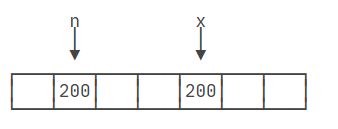
然后,执行int x = n;这行代码时,JVM会再次在内存中为变量x分配一个新的存储单元。由于n的当前值是200,因此JVM会将200复制到x的存储单元中。此时,x和n的值都是200,但它们存储在内存中不同的位置。
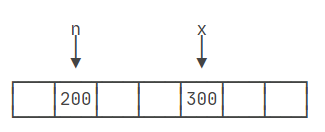
最后,执行x = x + 100;时,JVM首先会读取变量x的当前值200,然后将其与100相加得到300。接着,JVM会将300写入x的存储单元,从而更新x的值为300。这里值得注意的是,等号=在编程中用于赋值,而不是表示数学上的相等关系。因此,x = x + 100这行代码实际上是将x的值增加100,而不是检查x是否等于x + 100。
基本数据类型
基本数据类型是那些可以直接由CPU进行运算的数据类型。Java语言定义了以下八种基本数据类型:
-
整数类型:包括
byte、short、int和long。这些类型用于表示整数值,它们之间的主要区别在于能够表示的数值范围和所占用的内存空间。 -
浮点数类型:包括
float和double。这些类型用于表示带有小数点的数值,其中double类型的精度比float类型更高。 -
字符类型:即
char类型,用于表示单个的16位Unicode字符。 -
布尔类型:即
boolean类型,只有两个取值,true和false,通常用于逻辑判断。
在理解这些基本数据类型的区别时,需要了解计算机内存的基本结构。计算机内存的基本存储单元是字节(byte),每个字节由8位二进制数(bit)组成。这意味着一个字节可以表示从0到255(二进制的00000000到11111111)之间的数值。
内存单元通过从0开始的内存地址进行标识,每个内存地址对应一个特定的存储单元。这种结构类似于将每个内存单元比作一个房间,而内存地址则是每个房间的门牌号。
关于存储单位的换算,通常使用以下规则:1K等于1024字节,1M等于1024K,1G等于1024M,1T等于1024G。因此,一个拥有4T内存的计算机的字节数量可以通过连续的乘法计算得出:
4T = 4 x 1024G
= 4 x 1024 x 1024M
= 4 x 1024 x 1024 x 1024K
= 4 x 1024 x 1024 x 1024 x 1024
= 4398046511104不同的数据类型在内存中占用的字节数不同。例如,byte类型恰好占用一个字节,而long和double类型则各需要8个字节。这种不同的内存占用反映了它们能够表示的数值范围和精度上的差异。理解这些差异对于编写高效和准确的Java程序至关重要。
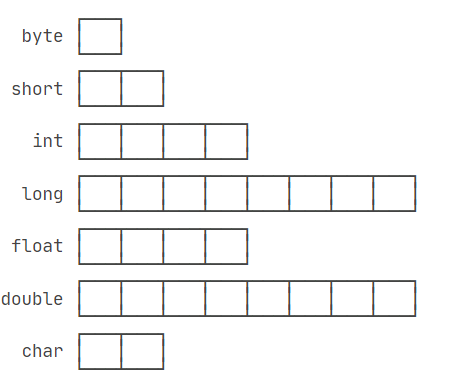
整型
对于整型类型,Java仅定义了带符号的整型,其中最高位bit用作符号位,0表示正数,1表示负数。这意味着整数的范围是有界的,并且每种整型都有它自己的最大和最小表示范围。具体来说:
byte类型的范围是-128到127。short类型的范围是-32,768到32,767。int类型的范围是-2,147,483,648到2,147,483,647。long类型的范围是-9,223,372,036,854,775,808到9,223,372,036,854,775,807。
下面是一个关于如何定义整型变量的示例:
public class Main {
public static void main(String[] args) {
// 定义int类型变量并赋值
int i = 2147483647; // int类型的最大值
int i2 = -2147483648; // int类型的最小值
int i3 = 2_000_000_000; // 使用下划线增强数字的可读性,值等于2000000000
int i4 = 0xff0000; // 十六进制表示的整数,等于16711680
int i5 = 0b1000000000; // 二进制表示的整数,等于512
// 定义long类型变量并赋值
long n1 = 9000000000000000000L; // long类型需要在数字后加L或l来表示
long n2 = 900; // 虽然没有加L,但这里的900是一个int值,int可以自动转换为long
// 下面的代码会导致编译错误,因为不能将long类型的值直接赋给int类型的变量
// int i6 = 900L; // 错误:类型不匹配:不能从long转换为int
}
}对于long类型的字面量,我们必须在其后添加L或l(尽管l与数字1容易混淆,因此通常推荐使用L)来明确它是一个long类型的值,因为Java会将不带后缀的整数默认为int类型。
浮点型
浮点类型的数,正如其名所示,主要用于表示带有小数点的数值。这类数值之所以被称为“浮点数”,是因为当它们用科学计数法表示时,小数点可以“浮动”在不同的位置,例如1234.5既可以表示为12.345×10^2,也可以表示为1.2345×10^3。
以下是定义浮点数的示例:
float f1 = 3.14f; // 定义一个float变量并初始化为3.14
float f2 = 3.14e38f; // 使用科学计数法表示一个非常大的数
// float f3 = 1.0; // 这行代码是错误的,因为不带f或F后缀的浮点数默认为double类型
double d = 1.79e308;
double d2 = -1.79e308;
double d3 = 4.9e-324;浮点数的表示范围非常广泛。float类型可以表示的最大正数大约是3.4×10^38,而double类型则可以表示的最大正数大约是1.79×10^308。这种广泛的表示范围使得浮点数在科学计算、工程计算和金融计算等领域中非常有用。
布尔类型
布尔(boolean)类型只有两个取值:true 和 false。这种类型经常用于逻辑运算和条件判断。在Java中,布尔类型常用于关系运算的结果,如比较两个数值的大小。
以下是一个简单的例子,展示了如何在Java中使用布尔类型:
boolean b1 = true; // 声明并初始化一个布尔变量b1,值为true
boolean b2 = false; // 声明并初始化一个布尔变量b2,值为false
// 使用关系运算符比较两个整数,并将结果赋值给布尔变量
boolean isGreater = 5 > 3; // 5大于3,所以isGreater的值为true
int age = 12;
boolean isAdult = age >= 18; // age不小于18,但因为age是12,所以isAdult的值为false
// 输出布尔变量的值
System.out.println("b1: " + b1); // 输出 "b1: true"
System.out.println("b2: " + b2); // 输出 "b2: false"
System.out.println("isGreater: " + isGreater); // 输出 "isGreater: true"
System.out.println("isAdult: " + isAdult); // 输出 "isAdult: false"虽然从理论上讲,存储布尔类型只需要1位(bit),但实际上,在Java虚拟机(JVM)内部,布尔类型通常会被表示为4字节的整数。这是因为JVM中的局部变量表通常是以4字节为单位进行对齐的,所以即使布尔类型只需要1位,它也会被占用4字节的空间。这样做可以简化JVM的设计和实现,同时提高内存访问的效率。
字符类型
字符类型char在Java中用于表示单个字符。这个数据类型不仅能够表示标准的ASCII字符集,还能够表示一个Unicode字符,这使得Java能够处理包括中文在内的各种语言的字符。
下面展示了如何在Java中使用char类型:
public class Main {
public static void main(String[] args) {
// 使用char类型定义并初始化一个变量a,表示ASCII字符'A'
char a = 'A';
// 使用char类型定义并初始化一个变量zh,表示Unicode字符'中'
char zh = '中';
// 输出变量a的值,即字符'A'
System.out.println(a);
// 输出变量zh的值,即字符'中'
System.out.println(zh);
}
}注意char类型使用单引号',且仅有一个字符,要和双引号"的字符串类型区分开。
引用类型
在Java中,除了上述的基本数据类型外,其余的所有数据类型都属于引用类型。引用类型的变量不同于基本类型,它们不直接存储数据值,而是存储一个“地址”,这个地址指向在内存中某个对象的实际位置。最常用的引用类型是String字符串。例如:
String s = "hello";
在这里,变量s是一个引用类型的变量,它存储的是字符串对象"hello"在内存中的地址。当我们对引用类型变量进行操作时,实际上是在操作这个地址所指向的对象。关于引用类型的深入讨论,特别是在类的概念中,我们会在后续章节中详细展开。
常量
在Java中,当我们定义一个变量时,可以使用final修饰符来将其变为常量。一旦一个变量被声明为常量,它就必须在定义时初始化,并且之后不能再被重新赋值。例如:
final double PI = 3.14; // PI是一个常量
double r = 5.0;
double area = PI * r * r;
// PI = 300; // 这将导致编译错误常量的主要作用是通过有意义的变量名来代替直接的数值或字符串,这样做可以提高代码的可读性和可维护性。例如,使用常量PI代替数学常数3.14,如果以后需要更改π的精度,只需修改常量的定义,而无需在代码中搜索并替换所有的3.14。
按照Java的命名习惯,常量名通常全部大写,并使用下划线分隔单词,例如MAX_VALUE。
var关键字
在Java中,var关键字允许我们在声明变量时省略类型名称,编译器会根据变量的初始化表达式自动推断出变量的类型。这在某些情况下可以使代码更简洁,尤其是当变量类型名称很长或复杂时。例如:
StringBuilder sb = new StringBuilder();
使用var关键字,这行代码可以简写为:
var sb = new StringBuilder();
编译器会根据右侧表达式的类型(new StringBuilder()返回的是StringBuilder类型),自动推断出变量sb的类型是StringBuilder。需要注意的是,var关键字不能用于方法的返回类型、构造函数的参数类型以及类的字段声明中。此外,使用var时,变量的初始化表达式必须是明确的,不能导致类型歧义。
变量的作用范围
在Java编程语言中,多行语句或代码块通常使用大括号 {} 来界定其范围。这种界定方式在控制语句中尤为常见,如条件判断(if)和循环(while、for 等)。每个控制语句的开始和结束都通过大括号来明确标识,确保编译器能够准确地识别出代码的执行顺序和范围。
例如,在一个嵌套的 if-while 结构中:
if (condition1) { // if语句开始
// 执行某些操作
while (condition2) { // while循环开始
// 循环体内的操作
if (condition3) { // 内嵌if语句开始
// 根据条件执行操作
} // 内嵌if语句结束
// 继续循环体内的其他操作
} // while循环结束
// 继续if语句内的其他操作
} // if语句结束在这种结构中,每一个控制语句的 {} 都定义了一个作用域,该作用域内的变量仅在该作用域内有效。一旦超出这个范围,尝试访问这些变量将会导致编译错误,因为这些变量在作用域之外是不可见的。
例如:
{
int i = 0; // 变量i在此处定义,其作用域从此处开始
{
int x = 1; // 变量x在此处定义,其作用域从此处开始
{
String s = "hello"; // 变量s在此处定义,其作用域从此处开始
} // 变量s的作用域在此处结束,不能在此之后访问s
String s = "hi"; // 新的变量s定义,与之前的s在不同的作用域
} // 变量x和新的变量s的作用域在此处结束
} // 变量i的作用域在此处结束在这个例子中,i、x 和 s 分别在其被声明的大括号内有效。当离开这些作用域时,这些变量就不再可用。值得注意的是,在同一个作用域内,不能声明两个同名的变量,即使它们的类型不同也不行。
在编写Java代码时,通常建议遵循作用域最小化的原则,即尽量将变量的作用域限制在它们实际被使用的最小范围内。这有助于提高代码的可读性和可维护性。同时,避免在不同的作用域内使用相同的变量名,以免导致混淆和意外的行为。