遍历数组
在Java编程的基础知识中,数组是一种非常重要的数据结构,它允许我们存储一系列相同类型的数据。为了有效地处理数组中的数据,我们需要对数组进行遍历操作。遍历数组通常涉及到访问数组中的每个元素,并可能对它们执行某些操作。
一种常见的遍历数组的方法是使用传统的for循环。这种循环方式允许我们通过索引来访问数组中的每个元素。下面是一个使用for循环遍历整数数组的示例:
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 4, 9, 16, 25 };
for (int i = 0; i < ns.length; i++) {
int n = ns[i];
System.out.println(n);
}
}
}在这个例子中,循环的初始条件是i=0,因为数组的索引从0开始。循环继续的条件是i < ns.length,这是因为当i等于ns.length时,它已经超出了数组的有效索引范围。在每次循环的最后,i的值会增加1(i++),以便在下一次循环中访问下一个元素。
除了传统的for循环,Java还提供了一种更简洁的遍历数组的方式,即增强型for循环(也称为for-each循环)。这种循环语法简洁,特别适合于那些不需要索引值的情况。下面是一个使用for-each循环遍历整数数组的示例:
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 4, 9, 16, 25 };
for (int n : ns) {
System.out.println(n);
}
}
}在这个例子中,我们不需要显式地使用索引来访问数组元素。在for-each循环中,每次循环都会自动获取数组的下一个元素,并将其赋值给变量n,然后我们可以直接对n进行操作。
选择使用哪种for循环取决于我们是否需要访问数组的索引。如果需要索引来进行某些操作,比如修改数组元素或者需要知道当前元素的位置,那么传统的for循环是更好的选择。如果我们只是想要访问和处理数组中的元素,而不需要索引,那么for-each循环会是更简洁和方便的选择。
打印数组内容
在Java中,当我们尝试直接打印一个数组对象时,通常只会得到数组在内存中的哈希码表示,例如[I@7852e922,这并不是我们想要的数组元素的实际内容。为了查看数组中的元素,我们需要遍历数组并打印每个元素。
在文章开头就是打印数组的例子,但写法仍然有些麻烦,尤其是当为了方便人来阅读,在其中加入合适的标点符号或分隔标志的时候。
幸运的是,Java提供了一个实用的方法Arrays.toString(),它可以将数组转换为一个字符串,其中包含数组所有元素的可读表示形式。使用这个方法,我们可以轻松地打印出格式化的数组内容:
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 1, 2, 3, 5, 8 };
System.out.println(Arrays.toString(ns));
}
}这段代码会输出数组ns的内容,格式为[1, 1, 2, 3, 5, 8],这是一个清晰且易于阅读的数组表示。这种方法是打印数组内容的首选方式,因为它简单、直观且易于理解。
数组排序
在编程中,对数组进行排序是一项基础而重要的任务。存在多种排序算法,如冒泡排序、插入排序、快速排序等,它们各有特点和适用场景。
冒泡排序是一种简单直观的排序算法,它通过重复遍历待排序的数列,比较每对相邻元素,并在必要时交换它们的位置。下面是一个使用冒泡排序对整型数组进行升序排序的示例:
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] ns = { 28, 12, 89, 73, 65, 18, 96, 50, 8, 36 };
System.out.println("排序前: " + Arrays.toString(ns));
for (int i = 0; i < ns.length - 1; i++) {
for (int j = 0; j < ns.length - i - 1; j++) {
if (ns[j] > ns[j + 1]) {
// 交换ns[j]和ns[j+1]的值
int tmp = ns[j];
ns[j] = ns[j + 1];
ns[j + 1] = tmp;
}
}
}
System.out.println("排序后: " + Arrays.toString(ns));
}
}冒泡排序的效率并不是最高的,特别是对于大数据集来说。在每一轮的循环中,最大的元素会“冒泡”到数组的末尾,这样在下一轮循环时就可以忽略掉这个元素。
在Java中,我们通常不需要手动实现排序算法,因为Java标准库已经提供了强大的排序功能。Arrays.sort()方法可以高效地对数组进行排序。使用这个方法,上面的冒泡排序示例可以被大大简化:
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] ns = { 28, 12, 89, 73, 65, 18, 96, 50, 8, 36 };
Arrays.sort(ns); // 使用Java标准库的排序方法
System.out.println(Arrays.toString(ns));
}
}这段代码将自动对数组ns进行升序排序,并且输出排序后的数组。使用Arrays.sort()不仅代码更简洁,而且效率更高,特别是对于大型数据集。因此,在实际开发中,推荐使用Java标准库的排序方法。
在Java中,数组排序是一种就地操作,这意味着排序过程会直接修改数组本身的内容。当你对数组使用Arrays.sort()方法时,原始数组的顺序会被更新,而不会创建一个新的数组。这一点对于理解数组排序的行为至关重要。
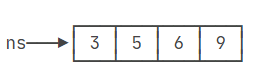
以一个整型数组为例:
int[] ns = { 9, 3, 6, 5 };在内存中,这个数组的初始状态可以表示为连续的内存地址,每个地址存储一个整数。

调用Arrays.sort(ns)后,这些整数的顺序会被调整为升序,数组的内存表示也随之改变,以反映新的顺序:
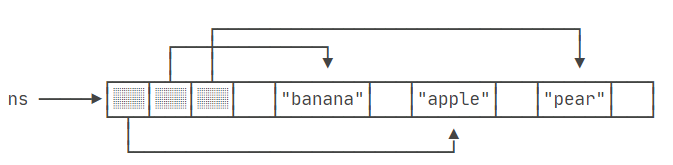
同样的,对于字符串数组,情况也是类似的:
String[] ns = { "banana", "apple", "pear" };排序前,数组中的字符串对象在内存中有自己的位置,而数组ns中的元素指向这些字符串对象的引用。
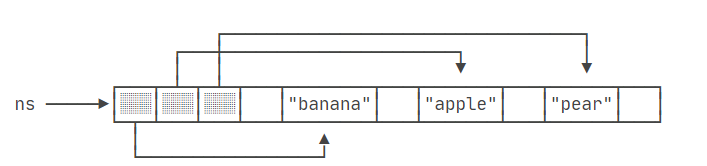
调用Arrays.sort(ns)后,字符串对象本身在内存中的位置不会改变,但是数组的元素引用会被重新排列,以反映字符串按字典顺序的排序结果: